Genes, the fundamental units of heredity, are composed of DNA and serve as instructions for producing proteins in the body. While some genes encode proteins, many others perform regulatory functions without directly producing proteins. In humans, genes vary widely in size, ranging from a few hundred DNA bases to over 2 million bases. The Human Genome Project, an international research initiative, estimated that humans possess approximately 20,000 to 25,000 genes.
Each individual inherits two copies of each gene, one from each parent. While most genes are consistent across populations, there are minor genetic variations, known as alleles, which contribute to unique physical traits in individuals. To facilitate research and communication, genes are assigned unique names and symbols, such as CFTR for the gene associated with cystic fibrosis, simplifying their identification and study.
History
Discovery of discrete inherited units:
Gregor Mendel, a scientist from the Austrian Empire (now Czech Republic), laid the groundwork for our understanding of genetics through his pioneering work with pea plants from 1857 to 1864. By meticulously observing traits in over 8000 pea plants, Mendel formulated the concept of discrete inheritable units. Though he didn’t use the term “gene,” his findings described these units as responsible for observable physical characteristics in offspring. This concept anticipated Wilhelm Johannsen’s later differentiation between genotype and phenotype.
Before Mendel’s discoveries, prevailing theories of heredity favoured blending inheritance, where parental traits mixed during fertilization. Charles Darwin proposed pangenesis, suggesting that parental contributions combined to form hypothetical particles termed gemmules.
Mendel’s work initially received little attention but was later rediscovered by scientists like Hugo de Vries, Carl Correns, and Erich von Tschermak in the late 19th century. De Vries, in particular, introduced the concept of “pangenesis” as individual carriers of hereditary traits, drawing on Darwin’s ideas.
Wilhelm Johannsen coined the term “gene” in 1909, while William Bateson introduced “genetics” in 1906. Despite this, some scientists, like Eduard Strasburg, continued to use “pangene” to describe the fundamental units of heredity at the time.
Discovery of DNA
Throughout the 20th century, progress in comprehending genes and inheritance continued. In the 1940s to 1950s, experiments established that deoxyribonucleic acid (DNA) serves as the molecular repository of genetic information. The structure of DNA was analyzed by Rosalind Franklin and Maurice Wilkins using X-ray crystallography, leading James D. Watson and Francis Crick to propose a model of the double-stranded DNA molecule. This model provided a persuasive hypothesis for the mechanism of genetic replication based on the pairing of nucleotide bases.
In the early 1950s, it was commonly believed that genes within a chromosome functioned as discrete entities arranged similarly to beads on a string. However, experiments conducted by Benzer, using mutants defective in the rII region of bacteriophage T4 between 1955 and 1959, demonstrated that individual genes possess a simple linear structure and are likely to correspond to a linear section of DNA.
This collective body of research established the central dogma of molecular biology, which initially proposed that proteins are translated from RNA, transcribed from DNA. However, exceptions to this dogma, such as reverse transcription in retroviruses, have since been identified. The modern study of genetics at the DNA level is referred to as molecular genetics.
In 1972, Walter Fiers and his team achieved a milestone by determining the sequence of a gene, specifically that of the bacteriophage MS2 coat protein. Subsequently, Frederick Sanger’s development of chain-termination DNA sequencing in 1977 significantly enhanced sequencing efficiency, making it a routine laboratory technique. An automated version of the Sanger method played a pivotal role in the early stages of the Human Genome Project.
DNA
The majority of organisms store their genetic information in long strands of DNA (deoxyribonucleic acid). DNA consists of chains made up of four types of nucleotide subunits, each containing a five-carbon sugar (2-deoxyribose), a phosphate group, and one of the four bases: adenine, cytosine, guanine, and thymine.
DNA forms a double helix structure, where two DNA strands twist around each other, with the phosphate-sugar backbone on the outside and the bases on the inside. Adenine pairs with thymine, and guanine pairs with cytosine, with specific hydrogen bonds between them.
DNA strands have directionality due to the chemical composition of the pentose residues of the bases. One end, known as the 3′ end, contains an exposed hydroxyl group on the deoxyribose, while the other end, the 5′ end, contains an exposed phosphate group. The two strands run in opposite directions, and nucleic acid synthesis, including DNA replication and transcription, occurs in the 5’→3′ direction.
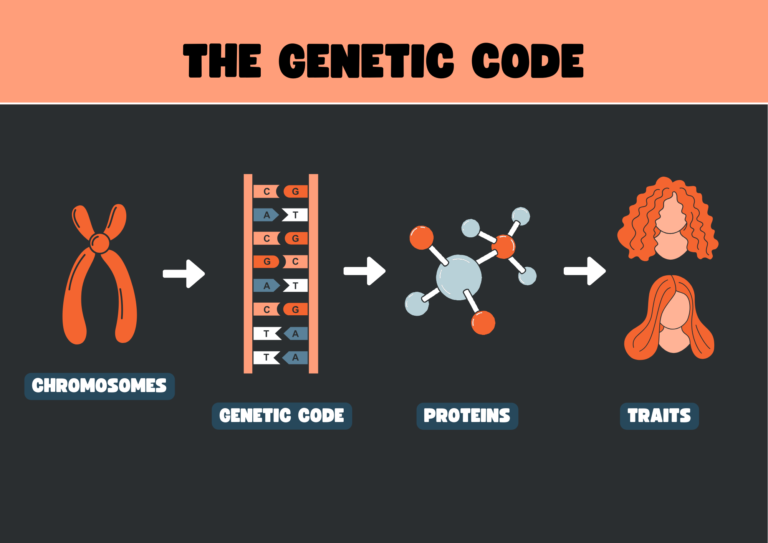
Genetic information encoded in DNA is expressed by transcribing the gene into RNA, a similar nucleic acid that uses ribose sugar instead of deoxyribose and uracil instead of thymine. RNA molecules are typically single-stranded. Genes encoding proteins consist of three nucleotide sequences called codons, which act as the “words” in the genetic “language.” The genetic code specifies the correspondence between codons and amino acids during protein translation and is almost identical across all known organisms.
Chromosome
The collection of genes within an organism or cell constitutes its genome, which can be housed on one or multiple chromosomes. Each chromosome comprises a lengthy DNA helix, serving as the blueprint for thousands of genes.
A chromosome’s specific gene location is termed its locus, with each locus hosting one gene allele. However, alleles within a population may exhibit variations in gene sequences.
The bulk of eukaryotic genetic material is stored on large, linear chromosomes, packaged within the nucleus alongside histone proteins to form nucleosomes, collectively termed chromatin. This chromatin structure, along with histone modifications, regulates gene accessibility for expression.
Eukaryotic chromosomes not only harbor genes but also include sequences essential for DNA replication and segregation during cell division, such as replication origins, telomeres, and the centromere.
Prokaryotes, like bacteria and archaea, typically house their genomes on a single circular chromosome. Additionally, certain eukaryotic organelles possess circular chromosomes with a limited gene count.
Prokaryotes may supplement their chromosome with small circular DNA molecules called plasmids, often carrying only a few genes, such as those for antibiotic resistance, transferrable between cells via horizontal gene transfer.
While prokaryotic chromosomes tend to be gene-dense, eukaryotic genomes often contain non-functional DNA regions. Though simple eukaryotes possess limited non-coding DNA, complex multicellular organisms, like humans, possess a significant portion of uncharacterized DNA.
Previously termed “junk DNA,” recent studies indicate a potential functional role for a large portion of non-coding DNA, challenging the validity of the term.
Genetic code
The sequence of nucleotides in a gene’s DNA dictates the sequence of amino acids in a protein via the genetic code. Three-nucleotide sets, called codons, each encode a specific amino acid.
In 1961, the concept that three consecutive DNA bases correspond to each amino acid was confirmed through experiments involving frameshift mutations in the rIIB gene of bacteriophage T4.
Moreover, a “start codon” and three “stop codons” denote the beginning and end of the protein-coding region. With 64 possible codons (four nucleotides at each of three positions, totaling 4^3), and only 20 standard amino acids, the code is redundant, meaning multiple codons can specify the same amino acid. This codon-to-amino-acid correspondence is almost universally conserved across all known living organisms.